从主机的世代演进看渲染技术的发展
最近一段时间恶补了一些图形学的历史,把 GPU gems 123 ,GPU pro 1234567 还有 GPU zen 中的render技术连贯的学习了一下。突然产生了这样的想法,就是主机的世代演进,除了硬件机能大幅提高之外,渲染技术也有世代级别的进化。大家对主机世代演进已经是非常熟悉了,而对图形技术演进应该还是比较陌生的。这次我就带着大家,随着主机世代的演进,看图形技术的发展。
- 世纪前 - 2D到3D的时代
- PS2/Xbox - 可编程管线的世代
- PS3/xbox360 - 延迟渲染的世代
- iPhone/android - 瓦片渲染来袭
- PS4/xbox one - Forward+
- 展望:PS5/Xbox two
世纪前 - 2D到3D的时代
文章的主题是渲染技术的演进,主要是3D实时渲染技术的跃进。但是为了完整性,还是记录一下上个世纪主机的一些显著图形技术进步。大家可以对号入座,想想有了这些技术之后,诞生了哪些或者说哪类游戏。
- FC,MD,: 卷轴滚动画面(横向/纵向卷轴)
- SFC: 实时缩放 (90年代初SEGA没有立即出家用机,而是出了光碟机版MD,后续又出了MD外挂32X)
- SS,PS1,N64: 光碟技术普及,3D CG技术,早期3D渲染技术(二次方程纹理->几何体光栅化)
- DC: 各向异性滤波,三线性插值
严格来说DC属于和ps2,NGC,xbox一个世代的主机,但是其推出时间是1998年11月27日属于世纪前。DC可以说是一台超越时代的主机,各向异性滤波,三线性插值这样的技术在实时渲染中大规模使用已经是很久以后了,在98年就支持网络对战远见异常,而莎木对成熟的开放世界和QTE系统设计无疑影响了后世众多游戏的设计思路。而莎木对于人物的渲染,尤其是皮肤和眼睛的渲染,也是非常的赞。
PS2/Xbox - 可编程管线的世代
上上世代渲染方面最大的进步,就是3D渲染技术从固定管线发展到了可编程渲染管线。本节完。
好吧,如果这样的话,那这节有点短。那就开启扩展知识模式吧,极简单介绍一下PS2实现可编程管线的方式。而这就不得不提一下PS2的大杀器 - Emotion Engine。
有人看到Emotion Engine,可能就和unity,unreal,cry engine这些游戏引擎混了,其实Emotion Engine并非游戏引擎,而是PS2的一个硬件模块。
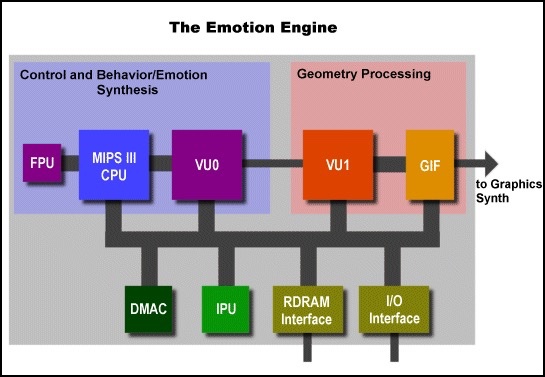
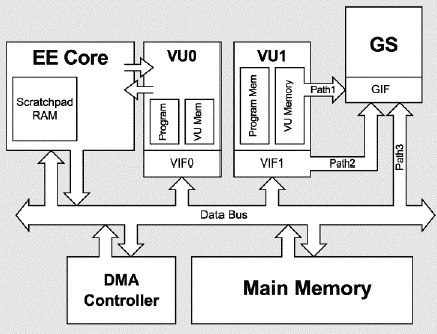
EE指整个PS2处理器和子系统的,也可以特指PS2的128位MIPS CPU。PS2还有两个专用向量单元(Vector Unit),VU0和VU1。VU0和EE CPU直联,可以处理开发者在C程序中编写的特殊 inline Assembly code。VU1集成在GS(Graphics Synthesizer)内部,VU1无法直接运行用户内嵌代码,需要用户用汇编编写程序,然后发送程序到VU1执行。
可以说,VU0就是PS2的顶点着色单元,VU1就是像素着色单元,两者直接的数据通过PS2的DMA(Direct Memory Access)传输。GS可以说是PS2的renderer,光栅单元和纹理单元都在GS中。在GS处理完成后数据发送给GIF(Graphics Interface),完成图像最终的显示工作。
PS2硬件各部分的详细介绍可以去glampert的blog或者PS2的wiki上查看。
PS3/xbox360 - 延迟渲染的世代
上个世代相比上上个世代,最大的特点,就是画面的突飞猛进。得益于 HLSL/Cg 这样的高级着色器语言流行,大家可以开发更多跟高级的材质和特效。众多Pixal renderman时代积累的材质也被移植到游戏中来。
更加复杂的材质带来了几个问题:
- 随着点光源增加,像素着色器负载成倍增加
- overdraw的代价极大(显卡都是先渲染,然后才像素舍弃)
- 随着材质复杂程度和场景内光源个数的变化,帧数剧烈波动
总结一下,就是上世代最大的瓶颈,就是像素处理能力不足
得益于RTT/FBO技术的成熟,以及上世代主机内存的大幅度增加(PS3 256m内存+256显存,xbox360 512m共享内存+10m超高速内存,PS2 64m内存+4m显存+2m声音专用内存,Xbox 128m内存),以及硬件支持贴图的数量增加,延迟渲染被大规模使用了。
overdraw最主要的情况,就是渲染了将要被舍弃的像素。而这以遮挡为最常见。那时候early-Z还不成熟,每个像素都是先渲染了,再深度测试。对于遮挡关系及其复杂的场景,overdraw就及其严重。处理这个情况,可以把渲染切分成两个阶段,第一个阶段只有顶点处理和光栅化阶段,不绘制材质,保存下来每个像素应该进行绘制的几何信息,然后再第二个阶段真正的进行绘制。
两个阶段就是两个render pass。而在两个render pass直接传递数据,就要依靠RTT技术了,需要设计一个G-buffer,用来存储场景的几何体信息。
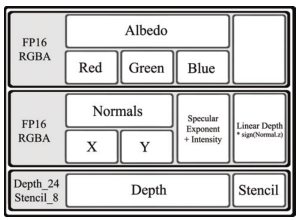
对于场景中的光源,可以在渲染的几何处理阶段和材质处理阶段的中间,额外增加一个光源处理阶段,用来记录各个像素累计光源的情况。
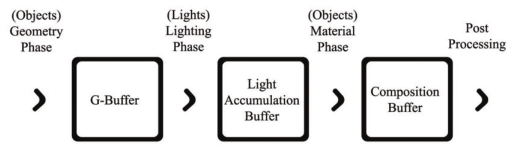
常见的延迟渲染就是这样,总结一下延迟渲染的优缺点
优点:
- 支持众多的动态光源
- 提供稳定的帧率
缺点:
- 消耗巨量的显存和显存带宽
- 对透明物体支持不佳
- 不支持硬件抗锯齿
iPhone/android - 瓦片渲染来袭
移动设备准确来说不是任何主机世代的一部分。但移动设备的几个特点:低性能,超低带宽,高分辨率。给渲染带来了新的挑战。解决这个问题的方式,就是瓦片渲染。解决移动平台渲染的相关问题的经验,直接影响了下个世代的图形技术,以及VR技术的发展。所以自然值得单开一章。
移动平台不使用传统延迟渲染的原因:
- 移动平台显存很小(支付不了庞大的G-buffer开销)
- 移动平台带宽很小(而分辨率很高,全屏幕分辨率的G-buffer的带宽开销更大)
- 移动平台像素处理能力也相对较弱(TAA这种软抗锯齿开销也很大)
接下来以mali GPU为例介绍一下移动平台的TBDR技术
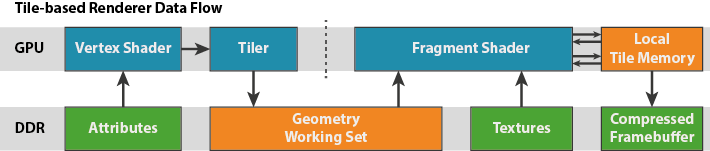
目标:减少渲染期间所需的功耗巨大的外部内存访问
不再以primitive为单位,执行完顶点着色器后立刻执行片段着色器。而是以rendertarget为单位,在一个rendertarget所有的顶点着色器执行完毕后,再执行片段着色器。执行顶点着色器的过程中,GPU将屏幕分割为16x16的区块,将订单数据分散发送到每个工作集。片段着色器一次只处理一个区块,计算完几个区块之后才访问下一个区块。
优点:
- 工作集的所有访问都属于本地访问,速度快、功耗低(传统模式需要占用的存储巨大导致只能放于内存之中)
- 区块足够小,我们实际上可以在区块内存中本地存储足够数量的样本,实现 4 倍、8 倍和 16 倍多采样抗锯齿。可提供质量高、开销很低的抗锯齿
- 在每个区块计算完成写回内存时,因为区块足够小,可以通过 CRC 检查将块的颜色与主内存中的当前数据进行比较(这一过程叫做“事务消除”—)如果区块内容相同,则可完全跳过写入,从而节省了 SoC 功耗
- 可以采用快速的无损压缩方案(ARM 帧缓冲压缩 (AFBC)),对逃过事务消除的区块的颜色数据进行压缩,从而进一步降低带宽和功耗
- 大多数内容拥有深度缓冲和模板缓冲,但帧渲染结束后就不必再保留其内容。如果开发人员告诉 Mali 驱动程序不需要保留深度缓冲和模板缓冲(理想方式是通过调用 glDiscardFramebufferEXT (OpenGL ES 2.0) 或 glInvalidateFramebuffer (OpenGLES 3.0),虽然在某些情形中可由驱动程序推断),那么区块的深度内容和模板内容也就彻底不用写回到主内存中。又大幅节省了带宽和功耗
- 完全由驱动实现,对于开发者来说是透明的,开发者只要当做普通的前向渲染即可
缺点:
任何基于区块的渲染方案的主要额外开销是从顶点着色器到片段着色器的中间构建工作集的过程。几何处理阶段的输出、各顶点可变数和区块中间状态必须写出到主内存,再由片段处理阶段重新读取
powerVR的TBDR还有Adreno的flex render技术大同小异,三家中powerVR实现的最好,Adreno实现的最差。flex render主打自动在前向渲染(TFR)和TBDR切换,但是实现的并不好,最近几年貌似也不再提flex render这个词了。
PS4/xbox one - Forward+
终于到本世代了,本世代的最重要的一个点,就是图像分辨率,从720P,提升到了1080P(后续机型甚至提升到了4k),1080P相比720P,所要填充的像素变为了2.25倍。对于显存和显存带宽都提出了新的需求。
接着聊一下硬件的发展,以xbox系为例,比较一下xbox 360和xbox one的差距
| \ | xbox 360 | xbox one |
|---|---|---|
| 理论浮点能力(TFLOPS) | 0.24 | 1.23 |
| 带宽(GB/s) | 22.4 | 68.3 |
| 共享内存容量 | 512m | 8g |
可以看到,理论浮点能力是原来的5倍,但是内存带宽不过原来的3倍,内存更是高达之前的8倍。
在2012年,迪士尼详细完整的阐述了BRDF模型,构建了完整的PBR理论。这也给本世代的引擎提了一个新的要求,就是TA可以自由的编写材质shader,美术也可以更自由的调整材质。而延迟渲染的材质阶段shader完全相同,美术人员的调节能力其实很小。
基于以上的问题,一直新型的渲染方式Forward+被提出了。F+渲染也分三个阶段:
- Z prepass:提前写一遍深度缓冲进行剔除防止overdraw
- Light culling:保存影响该像素的光源信息
- Final shading:最终渲染,和传统的前向渲染方式相同
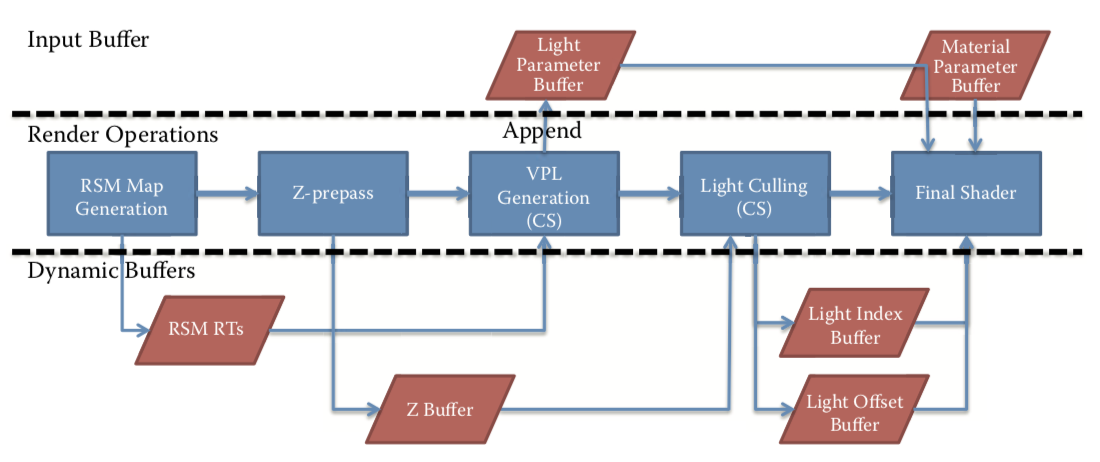
F+的Light culling和Final shading两个阶段最重要的特征,就是 基于瓦片。
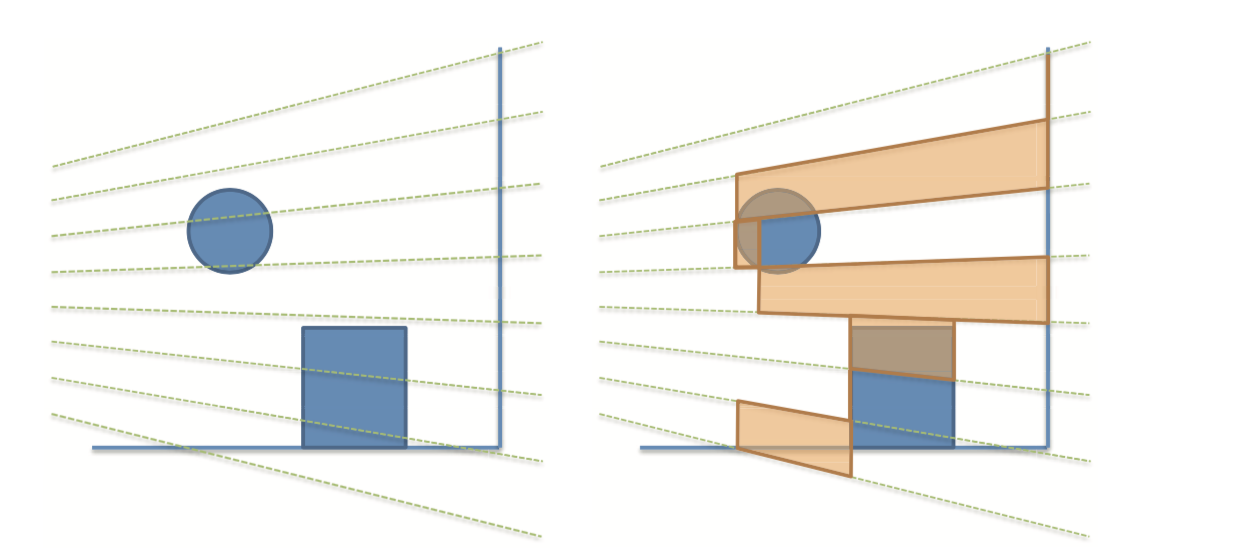
如同上文移动端渲染中所说,基于瓦片进行光源和图元剔除之后,绘制压力和带宽需求已经大大降低。因为之前进行了z prepass,还能将被遮挡的图元提前去除,进一步降低了overdraw。
F+渲染性能和延迟渲染的比较(数据来源于AMD)。
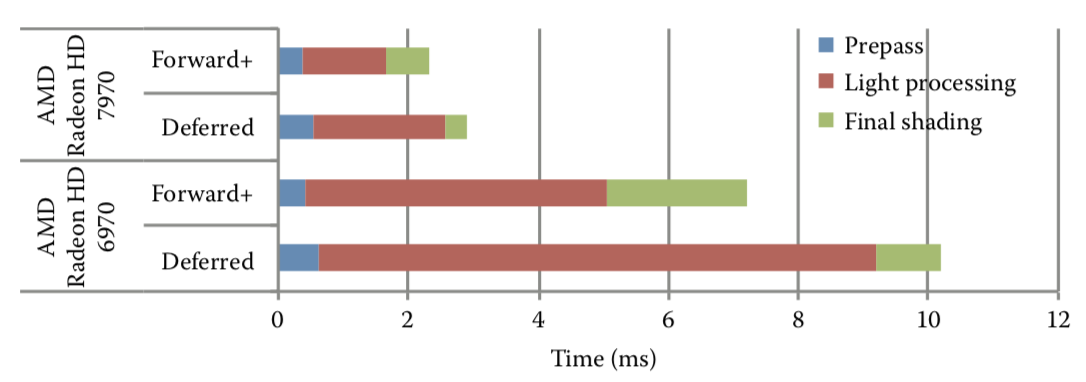
F+渲染改进了什么:
- 观察最近10年NV显卡其实就可以发现,显卡的像素性能提升了625倍,但是带宽提升不足10倍。可以说,本世代相比上个世代,渲染性能(遍历光源)损失不那么大,更多的drawCall不是问题,相反,带宽反而更瓶颈。
- 在每个瓦片内,采用前向渲染,这就带来了两个优势,支持半透明物体,支持硬件抗锯齿(MSAA)
- 支持更多的动态光源(每个瓦片受影响的动态光源都是culling过的)
- 材质系统设计更为自由,一套系统可以同时支持PBR和NPR(只要想的话)
- 几何无关的阶段可以使用计算着色器,大幅度缩短管线长度。并且瓦片直接可以并行(相比移动平台的TBDR)
- AMD在2012年的新图形API mantle,对于Sony和微软设计多线程渲染接口时提供了思路和原型。依靠多线程异步渲染,进一步增加了drawCall的数量
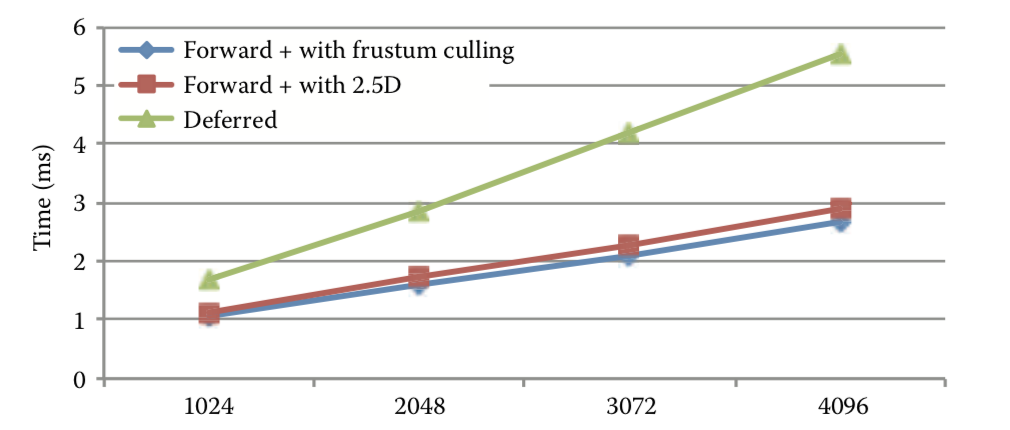
F+渲染的历史遗留问题:仍然需要保存巨大的G-Buffer和light Buffer。就是说,F+渲染相比延迟渲染,着重解决了带宽占用的问题,但是显存占用问题依旧严重。(这也是移动平台迟迟不用F+的原因)
F+渲染的改进。在GDC2016上,顽皮狗工作室展讲解了《神秘海域4》的优化细节。对于GPU来说,分支依旧是一个昂贵的操作(现在依旧可以简单的认为,增加一个分支操作,GPU性能折半)。所以引擎就要保证每个tile尽可能少的切换渲染状态,每个材质内部也要尽可能减少分支语句。
展望:PS5/Xbox two
今年E3大家都吃了不少饼,但是万众期待的PS5和Xbox two缺双双缺席。其实我以前有个观点,就是如果渲染技术没有重大突破的话,算不上次时代。PS4 pro/Xbox one x都是这样,1080P到4K提升固然明显,但是是暴力硬堆硬件堆出来的(PS4 pro整出的棋盘渲染算不上什么好点子,真的是不得已而为之)。所以我以前确实对PS5兴趣不大,如果索尼真的还整个不向下兼容,不是就呵呵了。
不过,在今年的GDC大会上,微软和NVIDIA联合展示了实时光线追踪技术,可以说给下个世代的主机和游戏,带来了新的可能。光线追踪对于实时渲染来说可是颠覆性的,它吧以前实时渲染所用的光栅化那套完全放弃了。一直以来,都是实时GI是图形学的圣杯。但是想不到的是这个圣杯拿到的如此之快。
在NV之后,AMD也不甘示弱,拿出了RadeonRay作为回应(RadeonRay相比RTX/DXR要慢,现在主要是Unity用来加速烘焙)。如果再加上前几年powerVR提出的openRL(causticGL,光线追踪和光栅化的一个混合渲染方案)。我们完全可以猜测下一世代主机会搭载实时光线追踪的机能,哪怕说是类似openRL那样的混合方案。
希望下一世代主机,能给我们带来惊喜吧。
Comments