AMD GCN的动态分支优化
wavefront
AMD GCN的硬件的最小单元是一个Compute Unit,简称CU。一个CU的结构如下。
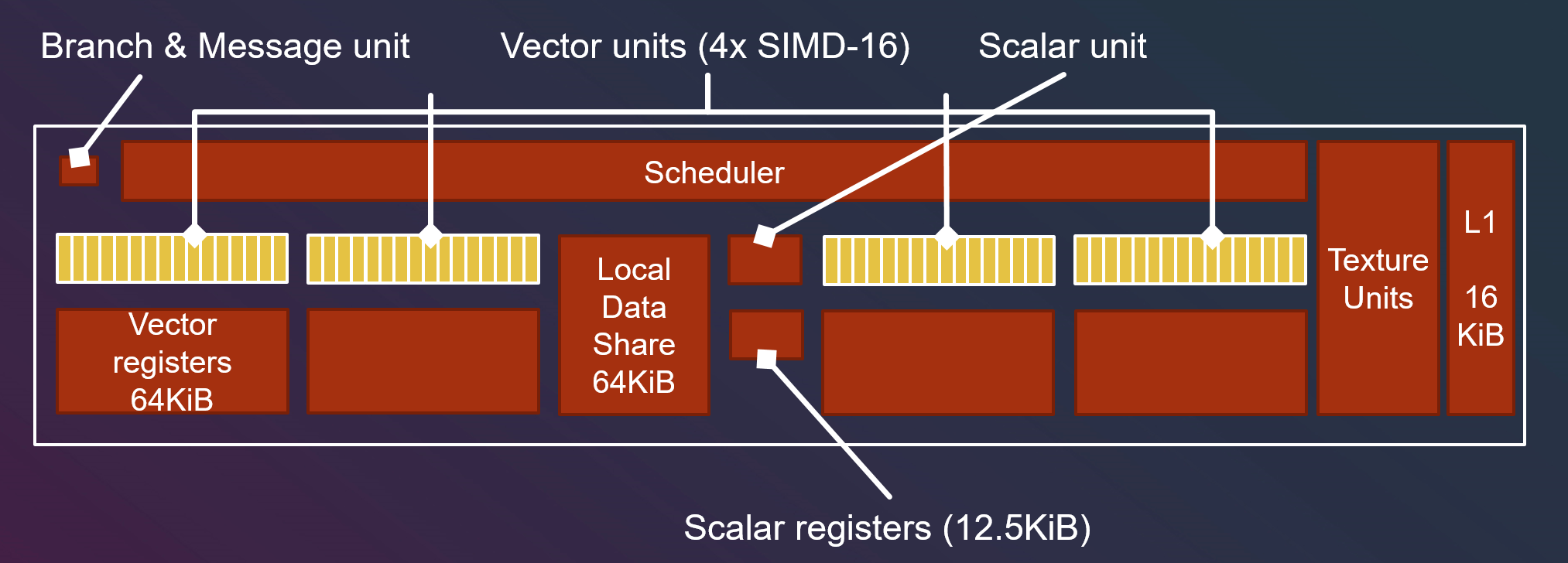
可知,一个CU包含一个调度单元,控制4个矢量单元;每个矢量单元包含16个SIMD处理器,以及一个64k的矢量寄存器;整个CU共享一个分支单元,一个标量单元,12.5k标量寄存器,64k LDS存储,一个贴图单元和16k L1缓存。
也就是说,64 threads是GCN GPU一次dispatch的最小单位,不足64也会被补齐为64。在编写compute shader时,thread group size最好为64的整数倍。并且,在实际开发时,如果compute shader的thread group size如果为64,则并不需要额外的同步操作,硬件本身会保证线程执行的同步(例如HLSL的GroupMemoryBarrierWithGroupSync,)。
这个最小调度的单位在AMD GCN GPU上被称为wavefront。
NVIDIA GPU中被称为warp,size为32
分支实现
wavefront概念最好的实践,就是分支代码的实现。
对于如下HLSL代码,其对应汇编如左图所示

该汇编的执行顺序为
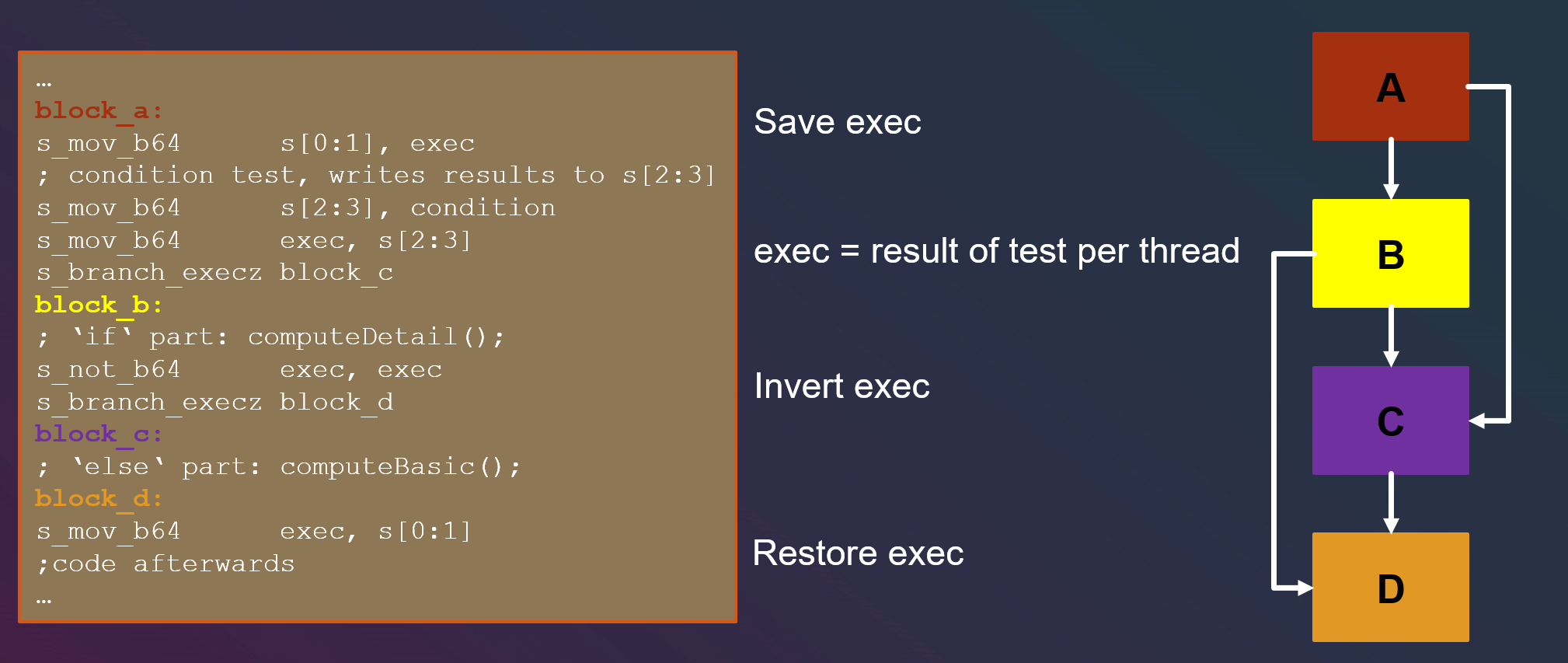
其中用来控制分支跳转的指令,就是s_branch_execz,当exec为0时跳转,否则继续执行。
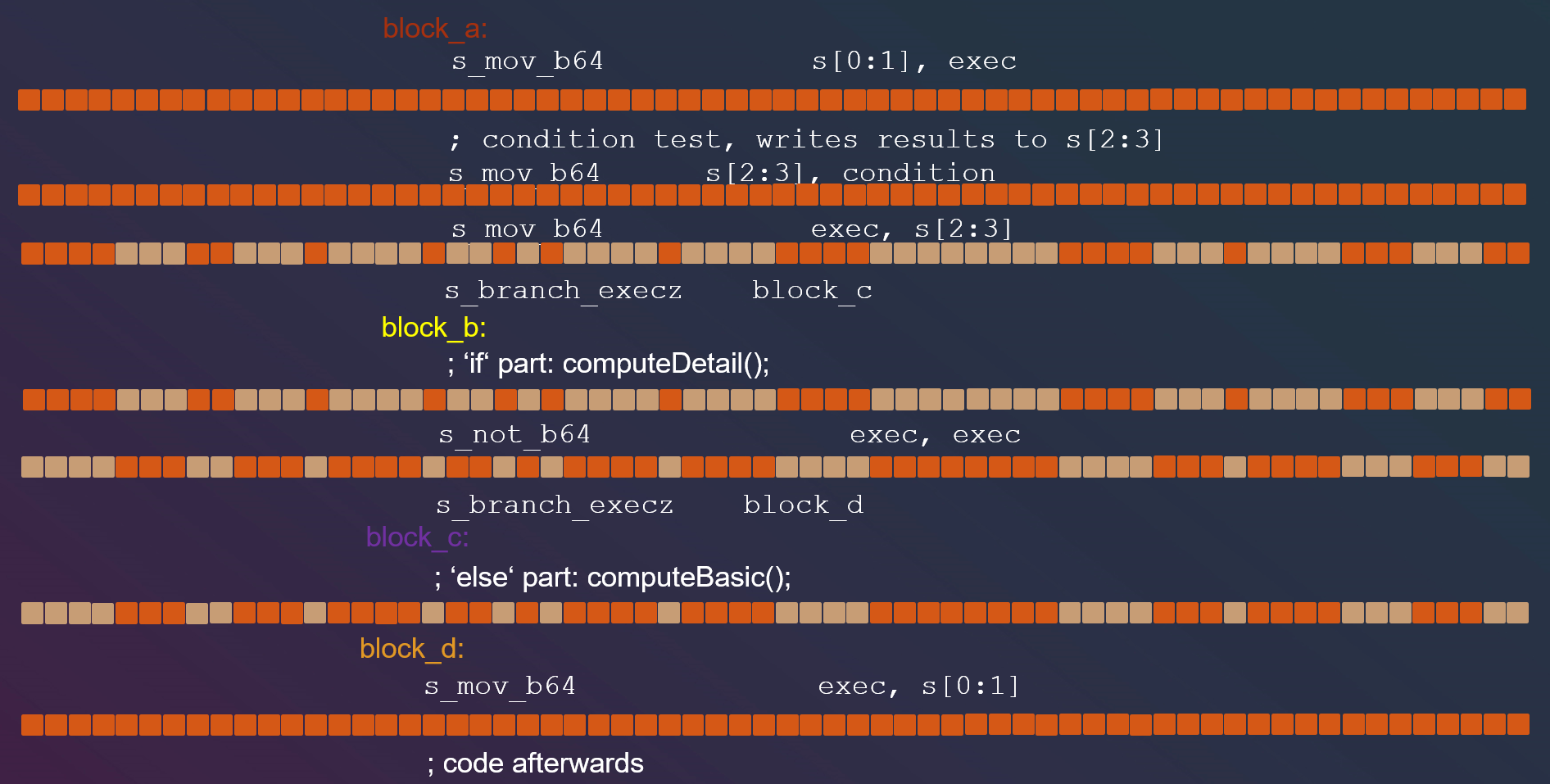
- condition的每一位代表一个wavefront中的每个线程的条件,运行过程中,首先要备份旧的exec值,然后将当前wavefront的每个判断的结果存到exec
- 判断exec的值,如果值为0就跳转到block c,否则顺序执行block b。本程序exec不是每一位均为0,故继续运行(执行if分支)
- 执行block b(if分支)后,将exec的值按位取反,并接着判断。本程序exec取反后依然不为0,运行block c(执行else分支)
- 在block c(else分支)运行结束后,将之前备份的旧exec值还原
exec是一个uint64,exec为0的条件,是exec中的每一位均为0
由上面的分析可知,通常情况下,GPU分支执行顺序为A->B->C->D。也就是说在一般情况下,动态GPU分支会执行所有的两个分支。但是,也有两个意外情况。也就是wavefront内所有分支全为真或者wavefront内所有分支全为假的情况。
先考虑所有wavefront内分支均为假的情况:
- 和通常情况相同
- exec的值为0,跳转到block c
- 运行block c(else分支),之后还原exec的值
也就是说,在wavefront内分支全为假的情况,GPU分支执行顺序为A->C->D,属于理想情况
先考虑所有wavefront内分支均为真的情况:
- 和通常情况相同
- 和通常情况相同
- 执行block b(if分支)后,将exec的值取反,取反后exec的值为0,直接跳转到block d
- 还原exec的值
结论
对于GCN GPU来说,如果一个wavefront内的动态分支条件相同,那么依然不会有通常动态分支的执行所有分支的损耗。
参考资料
[1] Compute Shaders - Optimize your engine using compute,Lou Kramer, AMD
Comments